随着生成式人工智能的进步并在各行业中广泛应用,在本地 PC 和工作站上运行生成式人工智能应用程序的重要性日益增加。本地推理可以减少消费者的延迟,消除他们对网络的依赖,并能够更好地控制他们的数据。 NVIDIA GeForce 和 NVIDIA RTX GPU 配备 Tensor Core,这是专用的 AI 硬件加速器,可为本地运行生成式 AI 提供强大的动力。 Stable Video Diffusion 现已针对NVIDIA TensorRT软件开发套件进行了优化,可在超过 1 亿台由 RTX GPU 驱动的 Windows PC 和工作站上解锁最高性能的生成式 AI。 现在,Automatic1111 针对流行的 Stable Diffusion WebUI 的 TensorRT 扩展增加了对 ControlNets 的支持,这些工具可以让用户通过添加其他图像作为指导来更好地控制以优化生成输出。 TensorRT 加速可以在新的 UL Procyon AI 图像生成基准测试中进行测试,内部测试表明该基准可以准确复制真实世界的性能。与最快的非 TensorRT 实现相比,它在 GeForce RTX 4080 SUPER GPU 上的速度提高了 50%。 更高效、精准的AITensorRT 使开发人员能够访问提供完全优化的 AI 体验的硬件。与在其他框架上运行应用程序相比,人工智能性能通常会提高一倍。 此外,稳定扩散 WebUI 的 TensorRT 扩展可将性能提升高达 2 倍,从而显着简化稳定扩散工作流程。 通过扩展的最新更新,TensorRT 优化扩展到 ControlNet——一组 AI 模型,通过添加额外条件来帮助指导扩散模型的输出。借助 TensorRT,ControlNet 速度提高了 40%。 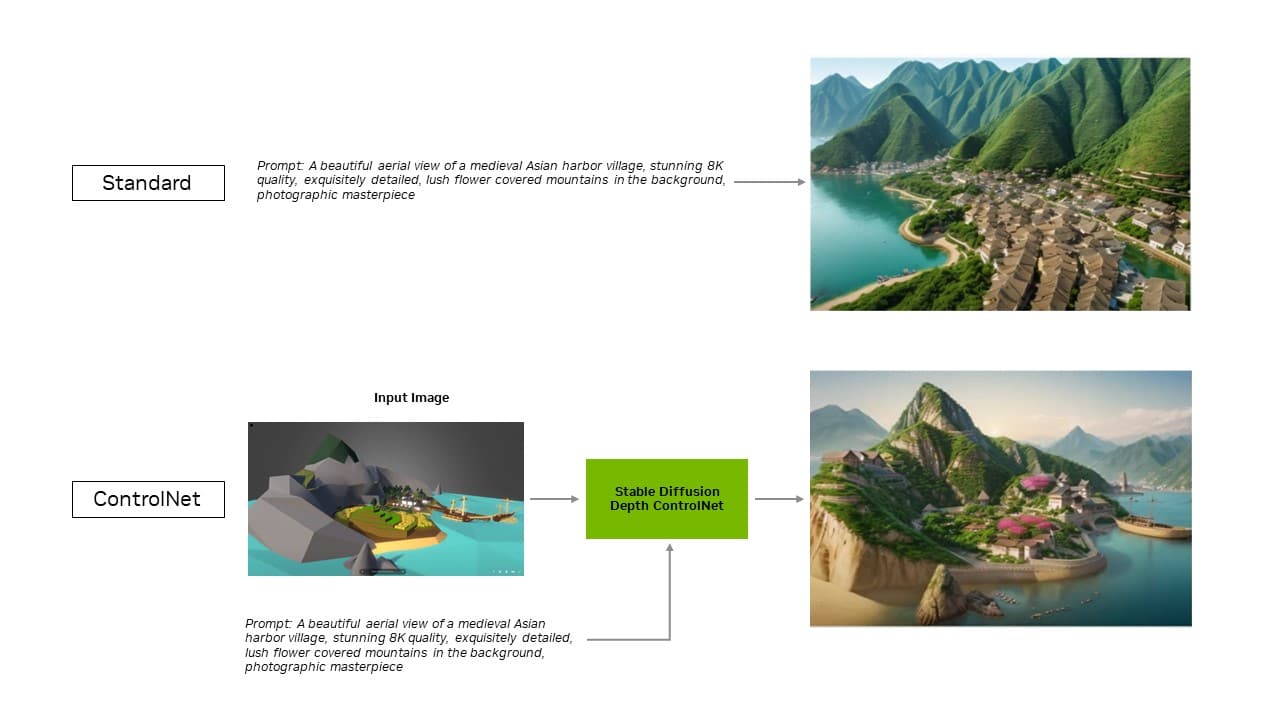 TensorRT 优化扩展到 ControlNet,以改进定制。 TensorRT 优化扩展到 ControlNet,以改进定制。用户可以指导输出的各个方面以匹配输入图像,这使他们能够更好地控制最终图像。他们还可以一起使用多个 ControlNet 以实现更好的控制。 ControlNet 可以是深度图、边缘图、法线图或关键点检测模型等。 由 TensorRT 加速的其他热门应用程序Blackmagic Design在 DaVinci Resolve 18.6 更新中采用了 NVIDIA TensorRT 加速。与 Mac 相比,Magic Mask、Speed Warp 和 Super Scale 等 AI 工具在 RTX GPU 上的运行速度提高了 50% 以上,最高可达 2.3 倍。 此外,通过 TensorRT 集成,Topaz Labs的照片 AI 和视频 AI 应用程序的性能提升了高达 60%——例如照片去噪、锐化、照片超分辨率、视频慢动作、视频超分辨率、视频稳定等——全部运行在 RTX 上。 将 Tensor Core 与 TensorRT 软件相结合,可为本地 PC 和工作站带来无与伦比的生成式 AI 性能。通过在本地运行,可以释放出几个优势: - 性能:用户体验到较低的延迟,因为当整个模型在本地运行时,延迟变得与网络质量无关。这对于游戏或视频会议等实时用例非常重要。 NVIDIA RTX 提供最快的 AI 加速器,每秒可扩展至超过 1,300 次 AI 万亿次操作(TOPS)。
- 成本:用户无需为大型语言模型推理支付云服务、云托管应用程序编程接口或基础设施成本。
- 始终在线:用户可以随时随地访问 LLM 功能,而无需依赖高带宽网络连接。
- 数据隐私:私人和专有数据始终保留在用户的设备上。
针对 LLM 进行优化TensorRT-LLM 是一个加速和优化 LLM 推理的开源库,包括对流行社区模型的开箱即用支持,包括 Phi-2、Llama2、Gemma、Mistral 和 Code Llama。任何人(从开发人员和创作者到企业员工和临时用户)都可以在NVIDIA AI Foundation 模型中尝试 TensorRT-LLM 优化的模型。此外,通过NVIDIA ChatRTX技术演示,用户可以看到在 Windows PC 上本地运行的各种模型的性能。 ChatRTX 基于 TensorRT-LLM 构建,可优化 RTX GPU 上的性能。 NVIDIA 正在与开源社区合作,开发适用于流行应用程序框架(包括 LlamaIndex 和 LangChain)的原生 TensorRT-LLM 连接器。 这些创新使开发人员可以轻松地将 TensorRT-LLM 与其应用程序结合使用,并通过 RTX 体验最佳的 LLM 性能。 | 





 发表于 2024-3-30 14:05
发表于 2024-3-30 14:05
 置顶卡
置顶卡